
- Classification adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Model itu sendiri bisa berupa aturan “jika-maka”, berupa decision tree, formula matematis atau neural network. Proses classification biasanya dibagi menjadi dua fase : learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk model perkiraan. Kemudian pada fase test model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi dari model tsb. Bila akurasinya mencukupi model ini dapat dipakai untuk prediksi kelas data yang belum diketahui.
-
Information Retrieval digunakan untuk menemukan kembali informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis. Salah satu aplikasi umum dari sistem temu kembali informasi adalah search-engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman-halaman Web yang dibutuhkannya melalui mesin tersebut.
Ukuran efektifitas pencarian ditentukan oleh precision dan recall. Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah dokumen yang ditemukan oleh search-engine. Precision mengindikasikan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen.
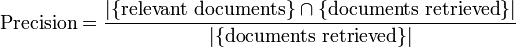
Recall adalah rasio jumlah dokumen relevan yang ditemukan kembali dengan total jumlah dokumen dalam kumpulan dokumen yang dianggap relevan.
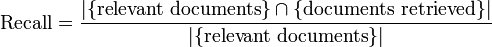
Dalam dalam hal ini, mendapatkan dokumen yang relevan tidaklah cukup. Tujuan yang harus dipenuhi adalah bagaimana mendapatkan doukmen relevan dan tidak mendapatkan dokumen yang tidak relevan. Tujuan lainnya adalah bagaimana menyusun dokumen yang telah didapatkan tersebut ditampilkan terurut dari dokumen yang memiliki tingkat relevansi lebih tingi ke tingkat relevansi rendah. Penyusunan dokumen terurut tersebut disebut sebagai perangkingan dokumen. Model Ruang Vektor dan Model Probabilistik adalah 2 model pendekatan untuk melakukan hal tersebut.
- algoritma HITS (Hypertext – Induced Topic Search). HITS menggunakan root set sebagai data awal, root set tersebut akan diperluas menjadi base set dan dari base set akan digunakan dalam perhitungan nilai authority dan hub.
Dari pengujian yang dilakukan berdasarkan backlink metric, penggunaan HITS pada information retrieval memberikan pengaruh yang baik terhadap nilai IAP namun tidak demikian halnya pada nilai precision. Penambahan batasan dokumen crawling dan jumlah root set tidak selalu memberikan peningkatan nilai precision, karena dapat dipengaruhi oleh jumlah inlink dan jumlah outlink dokumen tersebut. - PROLOG adalah kependekan dari PROgramming in LOGic, yang berarti pemrograman logika. Pemrograman Prolog menggunakan bahasa deklaratif, dimana pemrogram memberi fakta dan aturan untuk selanjutnya diselesaikan oleh Prolog secara deduktif sehingga menghasilkan suatu kesimpulan.
Hal ini berbeda dengan bahasa prosedural seperti Pascal, Fortran, C, atau yang sejenis, dimana pemrogram memberi perintah atau penugasan untuk memecahkan persoalan langkah demi langkah,sehingga sering disebut sebagai programming with assignment. Disamping itu, berbeda dengan pemrograman fungsional, pemrograman logika ini menggunakan relasi, bukan fungsi sehingga sangat sesuai untuk implementasi sistem pakar.