
1. Apa yang dimaksud supervised learning, unsupervised learning dan reinforcement learning?berikan contoh masing-masing?
Supervised Learning
Dalam teknik supervised learning, maka sebuah program harus dapat membuat klasifikasi – klasifikasi dari contoh- contoh yang telah diberikan.
Misalnya sebuah program diberikan benda berupa bangku dan meja, maka setelah beberapa contoh, program tersebut harus dapat memilah- milah objek ke dalam klasifikasi yang cocok.
Kesulitan dari supervised learning adalah kita tidak dapat membuat klasifikasi yang benar. Dapat dimungkinkan program akan salah dalam mengklasifikasi sebuah objek setelah dilatih. Oleh karena itu, selain menggunakan training set kita juga memberikan test set. Dari situ kita akan mengukur persentase keberhasilannya. Semakin tinggi berarti semakin baik program tersebut.
Persentase tersebut dapat ditingkatkan dengan diketahuinya temporal dependence dari sebuah data. Misalnya diketahui bahwa 70% mahasiswa dari jurusan Teknik Informatika adalah laki- laki dan 80% mahasiswa dari jurusan Sastra adalah wanita. Maka program tersebut akan dapat mengklasifikasi dengan lebih baik.
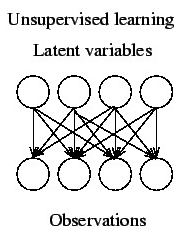
Unsupervised Learning
Teknik ini menggunakan prosedur yang berusaha untuk mencari partisi dari sebuah pola. Unsupervised learning mempelajari bagaimana sebuah sistem dapat belajar untuk merepresentasikan pola input dalam cara yang menggambarkan struktur statistikal dari keseluruhan pola input.
Berbeda dari supervised learning, unsupervised learning tidak memiliki target output yang eksplisit atau tidak ada pengklasifikasian input.
Dalam machine learning, teknik unsupervised sangat penting. Hal ini dikarenakan cara bekerjanya mirip dengan cara bekerja otak manusia. Dalam melakukan pembelajaran, tidak ada informasi dari contoh yang tersedia. Oleh karena itu, unsupervised learning menjadi esensial.
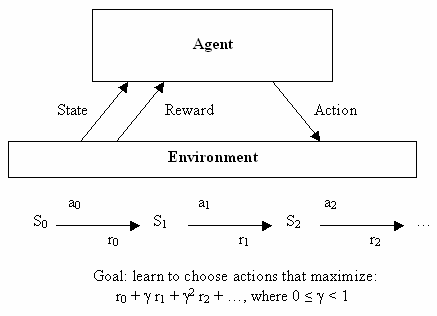
Reinforcement Learning
Reinforcement learning adalah sebuah teknik learning yang mempelajari aturan kontrol dengan cara berinteraksi dengan lingkungan yang masih asing. Ada 2 cara dalam teknik ini, teknik model-based dan teknik model-free.
Dalam teknik model-based, kita akan membuat sebuah subset berisi 4 tuple yang menggambarkan aksi, kondisi, hasil dan kondisi selanjutnya. Setelah mendapatkan subset yang cukup banyak maka kita dapat menghasilkan probability transition function dan reward function. Setelah mendapatkan kedua fungsi tersebut, kita dapat menggunakan dynamic programming untuk menghasilkan aturan yang paling optimal.
Dalam teknik model-free, kita tidak menyimpan subset yang berisi 4 tuple. Kita langsung menerapkan sebuah algoritma yang dapat langsung mengubah aturan kontrol menjadi lebih efisien.
2. Apa yang dimaksud dengan Learning Decision Tree dan berikan contohnya?
Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu.
Decision Tree menggunakan algoritma ID3 atau C4.5, yang diperkenalkan dan dikembangkan pertama kali oleh Quinlan yang merupakan singkatan dari Iterative Dichotomiser 3 atau Induction of Decision “3″ (baca: Tree).
Algoritma ID3 membentuk pohon keputusan dengan metode divide-and-conquer data secara rekursif dari atas ke bawah. Strategi pembentukan Decision Tree dengan algoritma ID3 adalah:
• Pohon dimulai sebagai node tunggal (akar/root) yang merepresentasikan semua data..
• Sesudah node root dibentuk, maka data pada node akar akan diukur dengan information gain untuk dipilih atribut mana yang akan dijadikan atribut pembaginya.
• Sebuah cabang dibentuk dari atribut yang dipilih menjadi pembagi dan data akan didistribusikan ke dalam cabang masing-masing.
• Algoritma ini akan terus menggunakan proses yang sama atau bersifat rekursif untuk dapat membentuk sebuah Decision Tree. Ketika sebuah atribut telah dipilih menjadi node pembagi atau cabang, maka atribut tersebut tidak diikutkan lagi dalam penghitungan nilai information gain.
• Proses pembagian rekursif akan berhenti jika salah satu dari kondisi dibawah ini terpenuhi:
1. Semua data dari anak cabang telah termasuk dalam kelas yang sama.
2. Semua atribut telah dipakai, tetapi masih tersisa data dalam kelas yang berbeda. Dalam kasus ini, diambil data yang mewakili kelas yang terbanyak untuk menjadi label kelas pada node daun.
3. Tidak terdapat data pada anak cabang yang baru. Dalam kasus ini, node daun akan dipilih pada cabang sebelumnya dan diambil data yang mewakili kelas terbanyak untuk dijadikan label kelas.
Beberapa contoh pemakaian Decision Tree,yaitu :
• Diagnosa penyakit tertentu, seperti hipertensi, kanker, stroke dan lain-lain
• Pemilihan produk seperti rumah, kendaraan, komputerdanlain-lain
• Pemilihan pegawai teladan sesuai dengan kriteria tertentu
• Deteksi gangguan pada computer atau jaringan computer seperti Deteksi Entrusi, deteksi virus (Trojan dan varians),dan lain-lain